Overview
💻 Demo1: Hide `__pycache__` in VSCode.
🌐 Demo2: Enlarge Font Size in Chrome.
📱 Demo3: Send SMS via Simple Messenger.
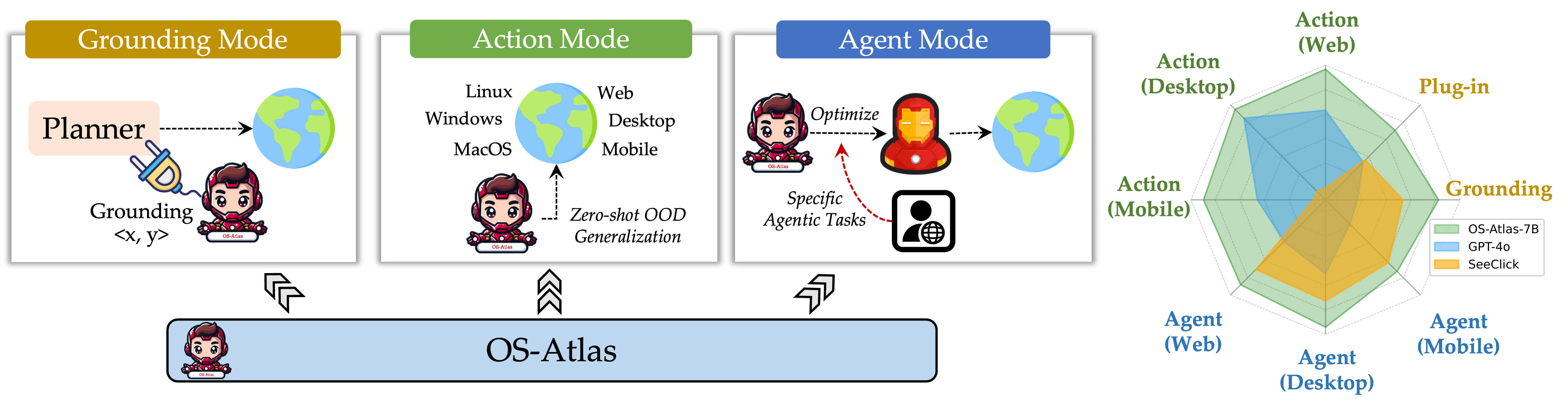
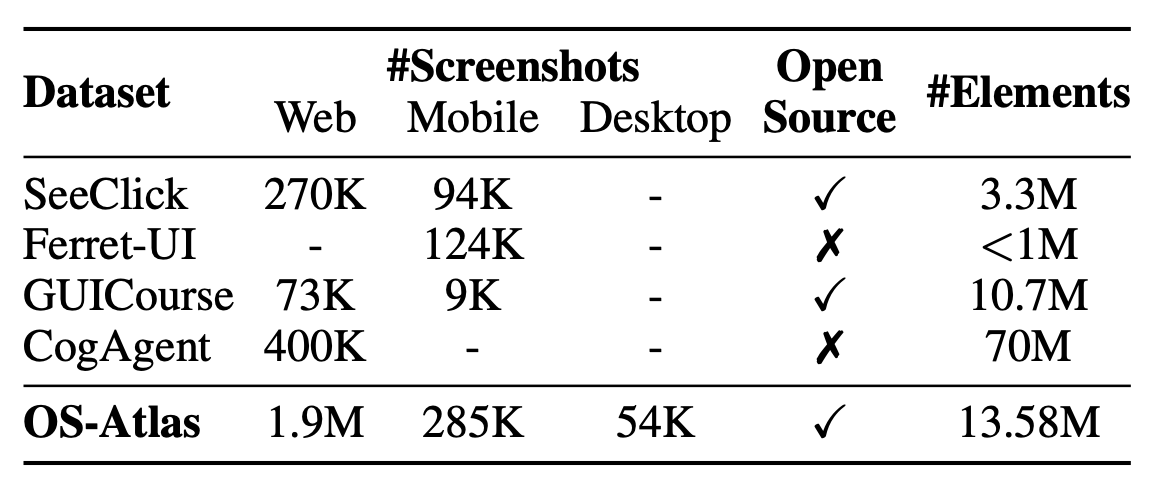
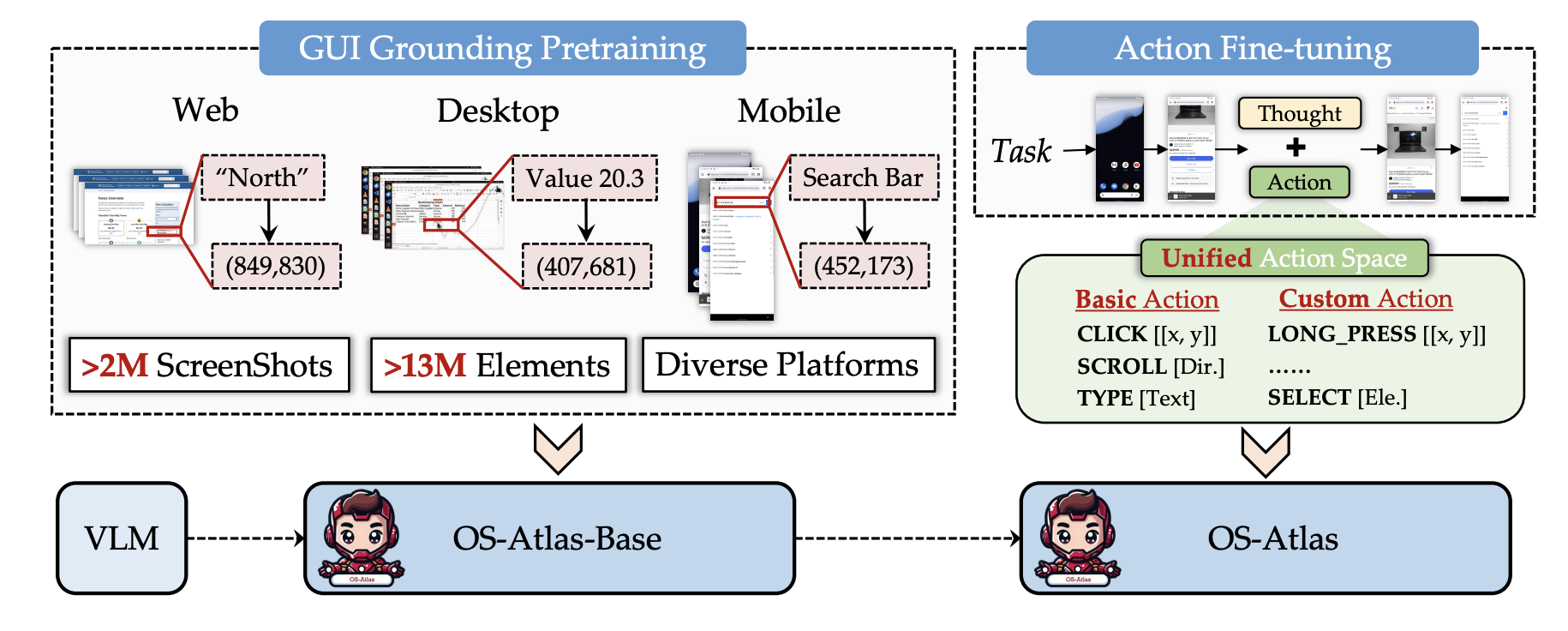
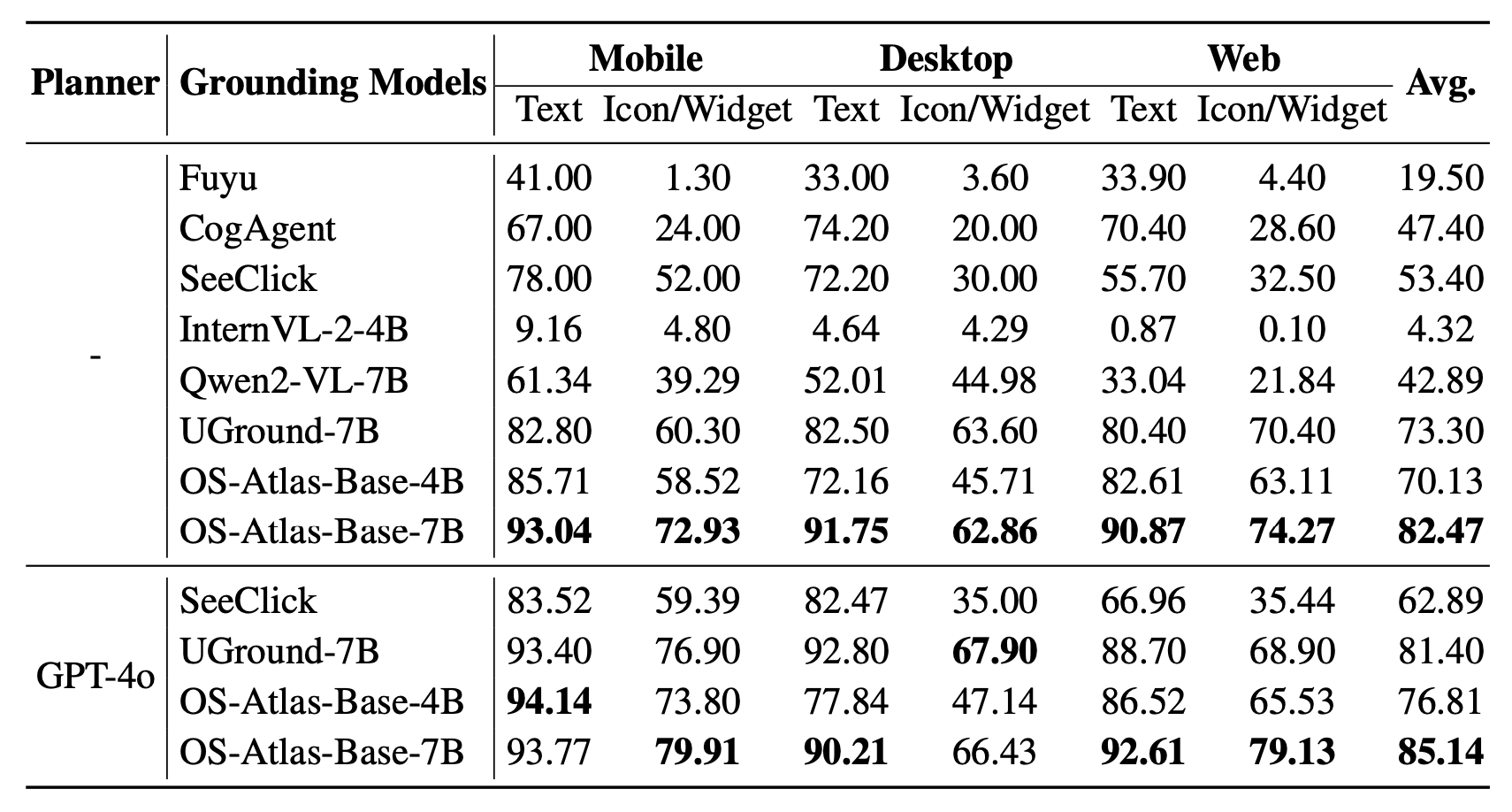
Existing efforts in building GUI agents heavily rely on the availability of robust commercial Vision-Language Models (VLMs) such as GPT-4o and GeminiProVision. Practitioners are often reluctant to use open-source VLMs due to their significant performance lag compared to their closed-source counterparts, particularly in GUI grounding and Out-Of-Distribution (OOD) scenarios. To facilitate future research in this area, we developed OS-Atlas—a foundational GUI action model that excels at GUI grounding and OOD agentic tasks through innovations in both data and modeling. We have invested substantial engineering effort into developing a toolkit for synthesizing multi-platform GUI grounding data. Leveraging this toolkit, we are releasing the largest open-source cross-platform GUI grounding corpus to date, which contains over 13 million GUI elements. This dataset, combined with innovations in model training, provides a solid foundation for OS-Atlas to understand GUI screenshots and generalize to unseen interfaces. Through extensive evaluation across six benchmarks spanning three different platforms (mobile, desktop, and web), OS-Atlas demonstrates significant performance improvements over previous state-of-the-art models. Our evaluation also uncovers valuable insights into continuously improving and scaling the agentic capabilities of open-source VLMs. All our data, code, and models will be made publicly available.
@article{wu2024atlas,
title={OS-ATLAS: A Foundation Action Model for Generalist GUI Agents},
author={Wu, Zhiyong and Wu, Zhenyu and Xu, Fangzhi and Wang, Yian and Sun, Qiushi and Jia, Chengyou and Cheng, Kanzhi and Ding, Zichen and Chen, Liheng and Liang, Paul Pu and others},
journal={arXiv preprint arXiv:2410.23218},
year={2024}
}